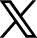

It is well known that great AI needs great data. It doesn’t matter if you are implementing a chatbot to reply to customer questions, creating an AI helper for the legal contracts, or training models to get the insights from academic papers; one thing remains constant: AI won’t work miracles without the right power source. The intelligence data pipeline can be built only through the right data source.
Think of swimming in a vast sea of information, yet being in need of insights. It is this paradox that characterizes the current business world: being overwhelmed by data and at the same time not getting the needed intelligence.
Here’s the simple truth: every bit of data doesn’t carry the same weight. In fact, close to 80–90% of a company’s most critical information lives in a state of unstructured, hidden within emails, PDFs, images, and other unstructured sources. To unlock the full potential of generative AI, organizations need more than the neatly organized numbers sitting in spreadsheets or databases. They need the deeper context and insights hidden within unstructured data; information that conventional systems tend to miss.
So far, the development of generative AI has marked a revolution, changing a situation that used to be a hard-to-overcome technical mess into the most exciting frontier in enterprise technology. A new era of intelligent data pipelines is here, where machines go beyond reading documents to truly understand them.
What’s new with processing unstructured data using an intelligent data pipeline?
The game has fundamentally changed with the emergence of intelligent data pipelines. Unlike their predecessors that followed rigid, rule-based logic, these new-generation pipelines leverage multimodal capabilities of Large Language Models to adapt, reason, and learn from the data they process.
Intelligent data pipelines have moved us far beyond the limitations of traditional OCR tools that focused solely on character recognition while missing the bigger picture. Modern LLMs embedded within these pipelines bring revolutionary capabilities to the table. On the extraction front, they’re remarkably adaptable, handling complex document layouts with ease while reducing errors that plagued older systems. They seamlessly process documents in multiple languages, extract meaningful relationships and context rather than just raw text, and handle multimodal elements including images, tables, and mixed-format content within the same document.
The intelligent data pipeline revolution: From automation to understanding
The transformation capabilities of intelligent data pipelines are equally impressive. With the power of LLMs, these pipelines can effortlessly organize data to match different database formats, adjust to new structures on the fly, and reason through information to produce smarter, more valuable transformations.. They enrich datasets with derived metrics, metadata, and relationships that traditional tools simply couldn’t generate; all while the data flows through the pipeline in real-time.
Perhaps most importantly, intelligent data pipelines are driving organizations from the traditional ETL model to a more adaptive ELT approach. Instead of spending time writing fixed rules or relying on OCR alone, many companies now use LLM-based pipelines that understand and extract information through smart prompt design. What used to take weeks of development and maintenance can now be done instantly through intelligent, automated workflows that make data extraction almost effortless compared to older systems. These pipelines don’t just move data; they understand it, validate it, and optimize it for downstream AI applications and analytics.
Key components of successful pipelines
Human-in-the-loop validation
Even with 98-99% accuracy, intelligent pipelines benefit from strategic human oversight. Rather than reviewing every extraction, sophisticated systems identify low-confidence predictions and route them for human validation. Companies that adopt intelligent data pipelines today are laying the groundwork for the next wave of AI-powered business operations.
Quality assurance mechanisms
Intelligent pipelines embed validation throughout the process. They check for completeness, verify data types match expected schemas, flag anomalies, and maintain audit trails. Some advanced implementations use dual-LLM architectures where one model extracts and another validates, dramatically reducing hallucinations and ensuring reliability.
Scalability and performance
Processing millions of documents demands careful optimization. Leading pipelines implement parallel processing, intelligent caching to avoid redundant API calls, incremental processing for updated documents, and adaptive batch sizing based on document complexity. These optimizations mean the difference between pipelines that crawl and those that fly.
Integration ecosystem
An intelligent pipeline doesn’t exist in isolation. It must seamlessly connect with your broader data infrastructure, feeding data lakes, populating vector databases for AI applications, updating operational databases, and triggering downstream workflows. The best pipelines offer pre-built connectors while maintaining flexibility for custom integrations.
Building an intelligent data pipeline for unstructured data extraction
Designing an intelligent data pipeline for unstructured data extraction involves orchestrating several key components, each enhanced by AI and LLM-based reasoning.
1. Smart ingestion layer
The ingestion layer captures data from multiple sources, such as documents, APIs, emails, images, or scanned files. Instead of static parsing, it uses AI-driven document classifiers and multimodal models to identify content type and structure automatically. This ensures that contracts, invoices, research papers, or handwritten notes are recognized, categorized, and queued for the right processing path.
2. AI-powered understanding and extraction
Once data enters the system, LLMs take over to interpret it contextually. Using prompt-driven extraction models, the pipeline can identify entities, relationships, and intent within documents.
For example, it can understand that a “delivery date” in one contract and a “shipment timeline” in another refer to the same data entity, even if phrased differently.
This stage replaces brittle, rule-based parsing with context-aware reasoning, allowing extraction to flexibly adapt to new document formats without manual reprogramming.
3. Transformation and schema alignment
Extracted data is then transformed into structured formats suitable for storage or analysis. Intelligent pipelines use AI to automatically map extracted fields to database schemas or API payloads.
Instead of hard-coded mappings, the system infers logical connections matching “invoice total” to “amount_due,” or merging fragmented address lines into a unified entity.
This step enriches data with metadata, inferred relationships, and domain-specific context, turning raw information into business-ready assets.
4. Validation and continuous learning
One of the hallmarks of intelligent data pipelines is feedback-driven optimization. Each processed document contributes to model fine-tuning. The system validates extracted results using confidence thresholds, rule-learning mechanisms, or downstream feedback.
Errors become learning opportunities, enabling continuous improvement without constant human intervention.
Real-world implementation patterns
Organizations deploying intelligent data pipelines typically follow one of several proven patterns.
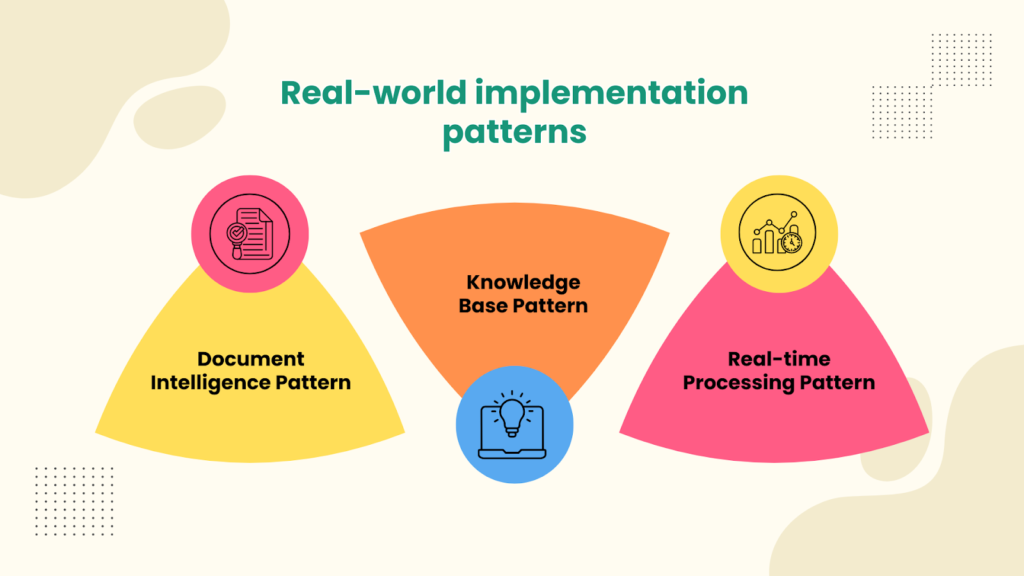
The document intelligence pattern focuses on high-value document processing such as contracts, invoices, medical records, and legal documents. Here, accuracy trumps speed, and pipelines often incorporate domain-specific fine-tuning and extensive validation.
The knowledge base pattern builds searchable repositories from unstructured content. These pipelines prioritize preserving context and semantic relationships, often feeding RAG systems or enterprise search platforms. They excel at turning scattered information into accessible, queryable knowledge.
The real-time processing pattern handles streaming unstructured data from customer support tickets, social media mentions, and system logs. These pipelines prioritize low latency and incremental processing, delivering insights within seconds rather than hours or days.
The next frontier in unstructured data processing
The rise of intelligent data pipelines marks a decisive turning point in how enterprises handle unstructured data. By combining the interpretive power of LLMs with the scalability of modern data infrastructure, these systems transform messy, chaotic information into clean, contextual, and connected intelligence. They don’t just automate extraction-they enable understanding at scale.
Organizations that invest in intelligent data pipelines today are effectively building the foundation for the next generation of AI-driven operations. Whether powering advanced analytics, generative AI applications, or real-time decision systems, these pipelines are becoming the central nervous system of enterprise intelligence.
This is exactly where Xtract.io’s Unstructured Data Extraction Solution leads the way. Built to simplify and accelerate unstructured data processing, Xtract.io combines AI-driven automation, advanced extraction models, and intelligent data orchestration to deliver high-quality, ready-to-use data for downstream systems. It enables enterprises to extract context, meaning, and structure from any source, such as documents, images, or reports, at scale and with precision.
In the age of cognitive automation, one principle stands clear:
Your AI is only as intelligent as your data pipeline.








