How we solved the problem
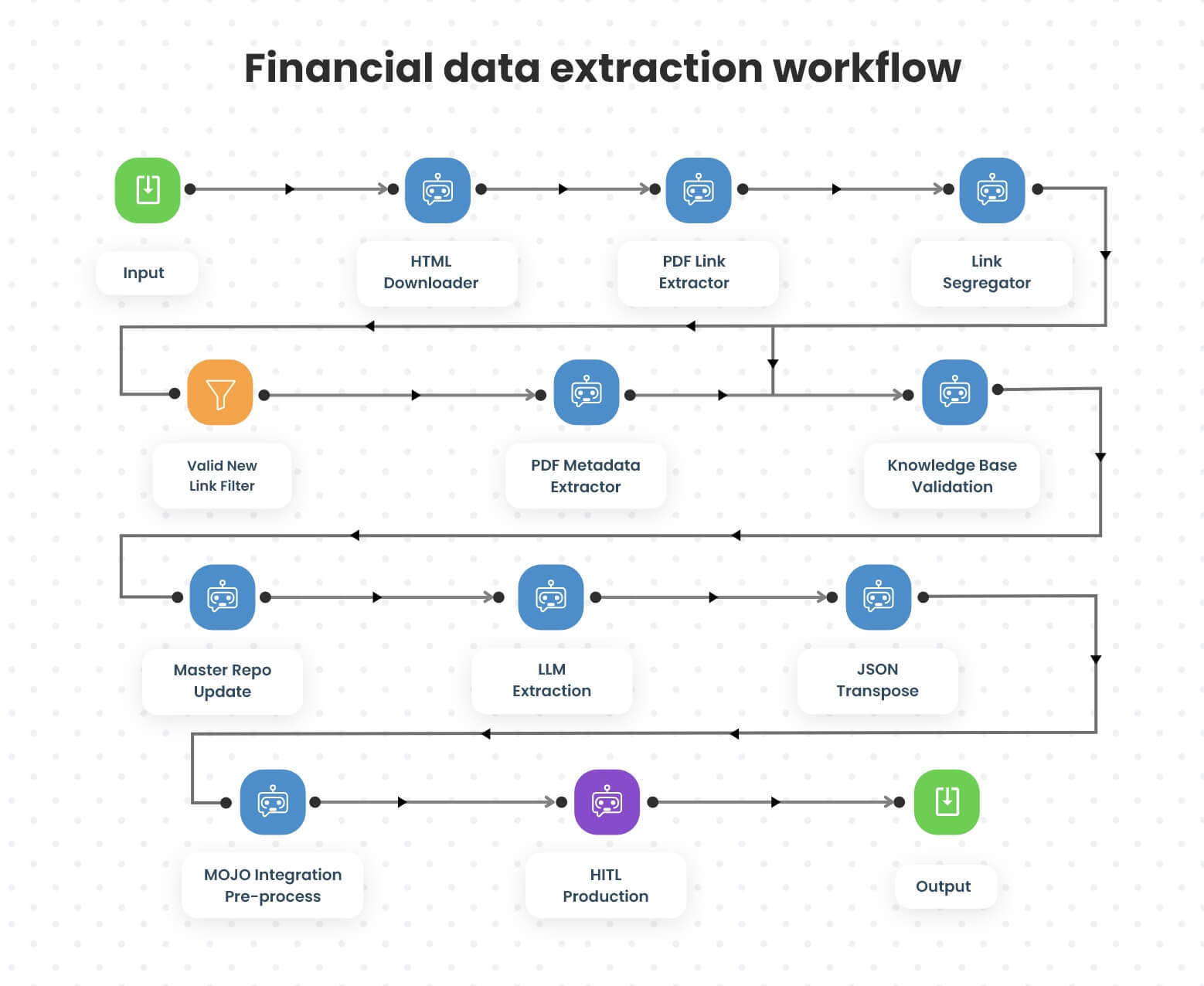
XDAS provided a holistic solution for financial data automation, starting with optimized website monitoring and automated data extraction from data sources to ensure timely data retrieval. Captured metadata was validated, structured, and stored to eliminate duplication and noise. AI-powered analysis offered deeper insights, while Human-in-the-Loop (HITL) validation ensured accuracy and quality. This streamlined approach enabled compliance-ready reporting and enhanced decision-making.
Automated data collection and link processing
Handling data from complex site structures, including static, dynamic, script-loaded, login-based, and CAPTCHA-protected sites, was addressed by deploying an HTML downloader to fetch offline HTML pages from specified URLs.
A PDF link extractor parsed these pages to identify new PDF links validated and categorized by a link segregator bot. The PDF downloader bot seamlessly handled the downloading of validated PDFs, ensuring accurate and efficient data extraction.
Metadata extraction and knowledge validation
XDAS utilized a PDF Metadata Extractor to process the documents and pull critical metadata from each PDF. This step was crucial to handling multilingual data, ensuring structured data processing across diverse content types. The metadata was then cross-checked against a knowledge base to ensure consistency and eliminate irrelevant or duplicate entries. This validated metadata was updated in real-time in the master repository, providing an up-to-date and reliable data source for further stages.
LLM-based financial data extraction
Advanced LLM extraction techniques were applied, using tailored prompts to extract the relevant financial data from the documents. The extracted data was then formatted into a JSON Transpose to match the client’s specifications, ensuring compatibility for easy integration with other systems.
HITL validation
XDAS integrated MOJO for a human-in-the-loop approach to ensure high-level accuracy. Trained human agents reviewed flagged records during HITL curation and validation. Final validation through HITL quality control ensured accuracy and consistency before transferring the data to the final repository for reporting and analysis.
The outcome was a streamlined, error-free data extraction process that enabled real-time insights and informed decision-making. By automating the flow from data extraction to validation and reporting, XDAS helped the client manage and analyze complex financial data, enabling better decision-making and compliance-ready reporting.

 Go beyond automation and turn unstructured data into action
Go beyond automation and turn unstructured data into action
 Streamline data and turn ideas into workflows with a robust data automation suite
Streamline data and turn ideas into workflows with a robust data automation suite
 Empowering innovation through purposeful partnerships.
Empowering innovation through purposeful partnerships.